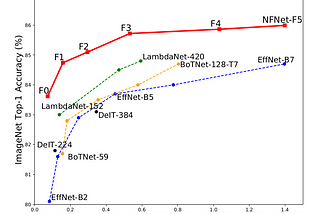
Adedeji OluwadamisolainAIGuysPaper Review: High-Performance Large-Scale Image Recognition Without Batch NormalizationTraining a deep network is very hard, as networks are prone to vanishing or exploding gradients. This problem was solved by the…Dec 7, 20211Dec 7, 20211